
we are developers
Desenvolvimento
Tem 10 artigos publicados com 10000 visualizações desde 2016
Após estudar mídia e computação em Berlim, Christine agora trabalha como desenvolvedora front-end e cientista de dados na webkid.io.
Se você quiser trabalhar com uma grande quantidade de dados não classificados e não marcados, existem algumas técnicas de aprendizado de máquina que podem ser úteis para você. Uma tarefa comum nessa área é a classificação de textos. Neste artigo, você vai ter uma ideia básica de como isso pode ser conseguido usando o chamado Naive Bayes Classifiers e como uma classificação simples de documento pode ser implementada em JavaScript.
DEMO
A ideia geral de aprendizado de máquina supervisionado é que você treina um sistema com dados rotulados. Um algoritmo de aprendizagem de máquina é alimentado com os dados do conjunto de treino. Ao treinar o sistema, um classificador é gerado. Usando-o, o sistema de treinamento é então capaz de classificar os dados desconhecidos, não marcados, com base nas coisas que ele tenha aprendido.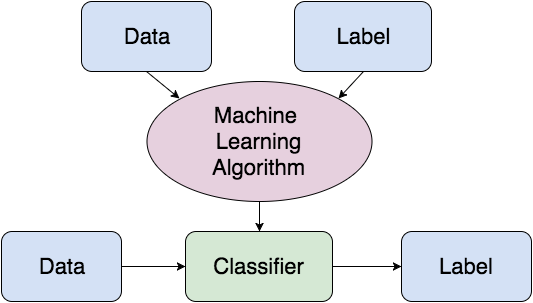
Um classificador que é muito comumente utilizado na classificação de texto é o Naive Bayes Classifier. Ele baseia-se na ideia do Teorema de Bayes, que é utilizado para calcular probabilidades condicionais. A ideia básica é descobrir qual a probabilidade de um documento pertencer a uma classe com base nas palavras no texto, ao passo que as palavras individuais são tratadas como recursos independentes. A fórmula simples para o cálculo pode ser escrita assim: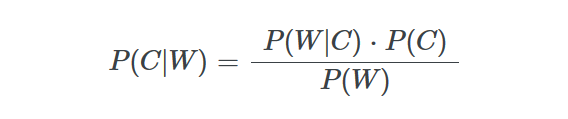
Uma explicação bem escrita e detalhada do Naive Bayes Classifier feita por Sebastian Raschka pode ser encontrada aqui.
Naive Bayes Classifier pode conseguir bons resultados para prever se um documento pertence a uma categoria ou outra. Possíveis casos de uso são:
Neste artigo, teremos um olhar mais atento para o último exemplo e criaremos um classificador que é capaz de distinguir entre mensagens de spam e não-spam (HAM). Para começar, a primeira coisa que precisamos é de um conjunto de treinamento rotulado ‘spam’ e mensagens “Ham”. Felizmente, essa coleção de textos SMS classificados pode ser encontrada neste link.
Esse conjunto é composto por 1.002 mensagens ham e 322 de spam, e pode ser baixado como um arquivo .txt. Eu trouxe o conteúdo em formato JSON para facilitar o uso. Como mencionado anteriormente, são necessários um treinamento e um conjunto de teste. O conjunto de treino é composto por 600 elementos (300 de cada classe), e o conjunto de teste contém 44 elementos (22 de cada classe).
Existem algumas bibliotecas JavaScript que podem ser utilizadas para a classificação de documentos, por exemplo:
Vamos ter um olhar mais atento ao Natural, que oferece funções para várias tarefas de processamento de linguagem e fará uso do BayesClassifier do Natural.
Depois de criar o classificador, os dados que devem ser treinados podem ser adicionados usando a função addDocument (). Essa função recebe como parâmetros um texto e o rótulo correto para esse texto. Nós podemos iterar sobre o conjunto de treinamento e adicionar cada elemento ao classificador. Depois que todos os dados foram adicionados, o classificador pode ser treinado.
Quando os textos são adicionados para o classificador, um pré-processamento é feito automaticamente. A string fica tokenizada, o que significa que ela é dividida em palavras simples. A partir dessas palavras, todas as chamadas palavras de parada são removidas. Palavras de parada são aquelas que aparecem frequentemente e são, portanto, não muito relevantes para o conteúdo. Alguns exemplos de palavras de parada são “a”, “um”, “e” … Além disso, as palavras são transformadas em sua forma raiz, o que é chamado de stemming. Esse pré-processamento do texto é feito pelo PorterStemmer do Natural utilizando a função tokenizeAndStem ().
Quando o treinamento é concluído, o classificador pode ser utilizado para prever a etiqueta de dados desconhecidos. Isso pode ser conseguido com a função classify(). O texto não marcado é transmitido como parâmetro e a etiqueta prevista é retornada.
E é isso! Usando nossos conjuntos de treinamento e teste, 100% dos dados de teste podem ser classificados corretamente. Para lhe dar uma impressão do que mais pode ser feito com essa técnica simples, criamos uma ferramenta que é capaz de classificar os tweets pelo nome dos candidatos presidenciais norte-americanos Hilary Clinton, Bernie Sanders e Donald Trump, que você pode encontrar aqui.
***
Christine Wiederer faz parte do time de colunistas internacionais do iMasters. A tradução do artigo é feita pela redação iMasters, com autorização do autor, e você pode acompanhar o artigo em inglês no link: http://blog.webkid.io/document-classification-in-javascript/
De 0 a 10, o quanto você recomendaria este artigo para um amigo?
Após estudar mídia e computação em Berlim, Christine agora trabalha como desenvolvedora front-end e cientista de dados na webkid.io.
Fique em dia com as novidades do iMasters! Assine nossa newsletter e receba conteúdos especiais curados por nossa equipe

Studio Live Code Blog
Dicas e tutoriais para nossos clientes.

